Posts
Caber insights on AI Governance: Security, answer quality, trustworthiness, and more.
Recent Posts

When Your Governance Tool Causes the Hallucination
Naïve AI guardrails don't just fail to prevent bad outputs. They actively create the conditions for worse ones.

Ten Misconceptions About Context in AI Systems
Most of what makes a chunk trustworthy lives outside the chunk. Here's why.
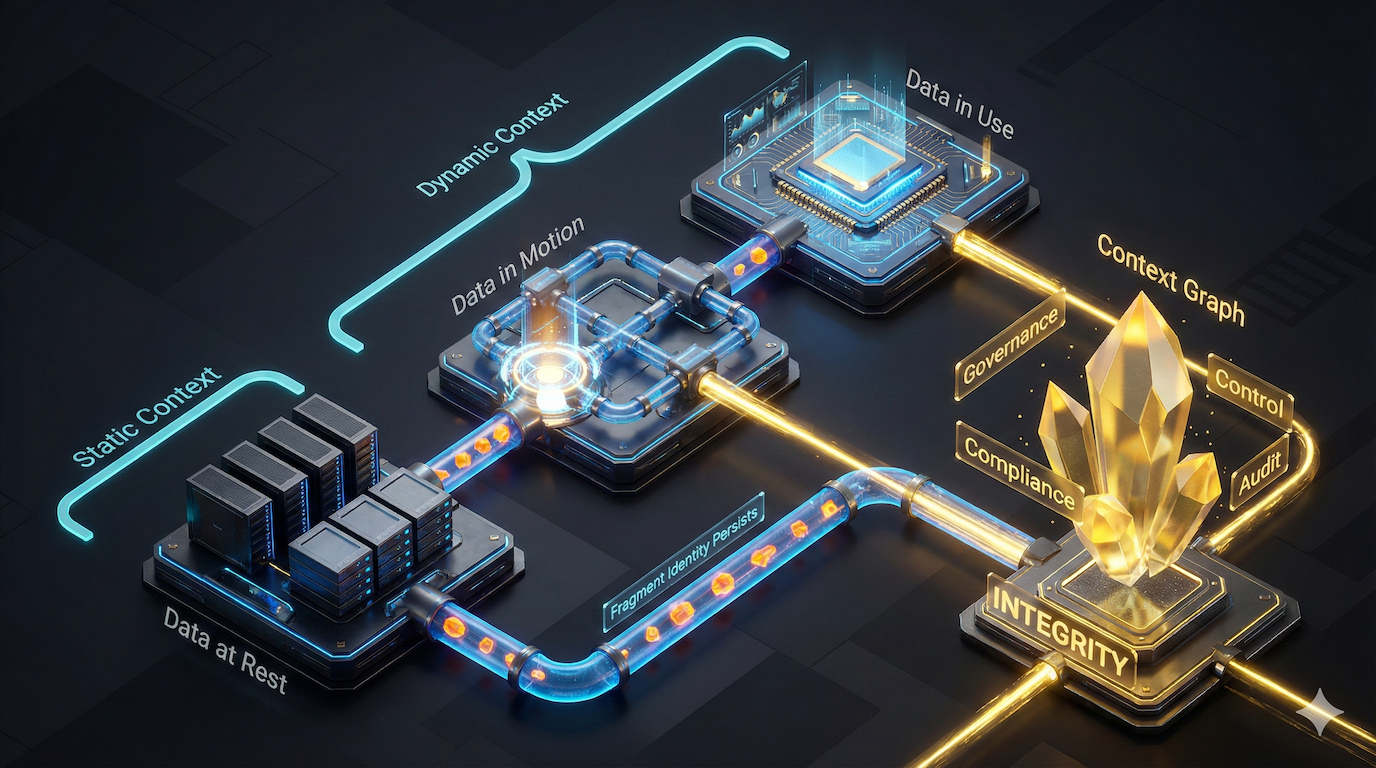
Context Graphs for Governance
Why AI governance breaks without binding static and dynamic context across how decisions are built

How Duplicate Data Kills Your RAG
Duplication of data across documents causes unseen biases in Retrieval Augmented Generation

Why Securing MCP Servers is the Wrong Approach (Part 3)
Security assumed endpoints = data. Then AI agents and MCP arrived and broke that link forever. Now we're guarding the wrong target.

Old Vulnerabilities are New Again! (MCP Part 2)
OAuth 2.0 promised to fix APIs. It failed. Now OAuth 2.1 promises to fix MCP. History repeating?
See Caber in Action
Want to take control of your AI initiaitives? Let us show you how.